Redash のクエリーの変更履歴を管理する工夫
先日「Redash でクエリーの変更履歴管理ってやってますか?」というような質問をいただいたので、その時話したことと、その後調べたことなどをメモとして書いておきます。
あくまで個人の意見として読んでいただきたいのですが、なにか参考になることがあればうれしいです。
クエリーの変更履歴を管理する工夫
API からクエリー情報を取得し、その値を利用する
私が実務で使用している方法はこのやりかたです。
Redash はほとんどすべての操作を API から呼び出すことができるので、ちょっとしたスクリプトを書いてクエリーの情報を取得し、自動的かつ定期的に Git にコミットするような運用をしています(実行間隔は5分毎ぐらい)
私は以前に記事で紹介した redashman を使用していますが、 現時点では redash-toolbelt が良い選択肢になるかもしれません。サンプルコードにはクエリーをエクスポートするような例もあるので、Python を読み書きしたことがあればすぐに理解できると思います。
ディスクのスナップショットを取得し、必要なときにリストアして履歴を追う
これは変更履歴の管理方法といえないようなものですが、案外見落とされている事かもしれないので書いておきます。
Redash は AMI などから気軽に立ち上げられる一方で、Redash が稼働しているサーバーの監視設定などが見落とされるケースもあるようです。
API から情報を取得する方法と違い、短い間隔で履歴を取得するのは難しくなりますが、IaaS 上のサーバーであれば、簡単にディスクイメージの定期的なスナップショットを取得できることが多いので、可能な限り1日1回はディスクのスナップショットを取得しておきましょう。
Redash が使用している PostgreSQL サーバーを RDS など外部に切り出している場合は、それぞれのサービスや環境でスナップショットなどの取得を検討してみてください。
この方法では、過去の状態を確認するためにリストアが必要になるため、気軽に履歴が確認することはできませんが「前日の状態でもいいから戻したい・比較したい」という状況には対応できます。
PostgreSQL のバックアップを取得し、必要なときにリストアして履歴を追う
こちらはディスクのスナップショットと似ていますが、Redash は内部的に PostgreSQL を使用していますので、ディスクのスナップショットが気軽に取れない環境では、PosrgreSQL のデータベースをバックアップしておくという方法もとることができます。
具体的な方法については PostgreSQL の話になるので割愛しますが、Redash のクエリーを保持している queries テーブルのみを指定して pg_dump でバックアップを取れば、ディスクのスナップショットより高頻度にバックアップを残すこともできますし、少し見づらさはありますが SQL として残しておくことで、リストアせずとも(ある程度は)バックアップ取得時点のクエリーを確認することもできると思います。
ディスクのスナップショットよりは少し手間になりますが、用途に合うようであれば検討する価値はあると思います。
PostgreSQL のトリガーを使って変更履歴を残す
これは手元の環境で試してみた程度のものではありますが、PostgreSQL のトリガーで queries の更新時に変更履歴を取得することもできます。
トリガーの具体的な設定については割愛しますが、比較的簡単に設定できるという利点もありながら、Redash のメタデータの理解や、今後の Redash アップデートの影響を受ける可能性がありますので、そういったリスクを考慮した上で導入を検討したほうがよいでしょう。
Redash の changes テーブルは使えないか?
Redash には changes というテーブルがあり、中を除くとクエリーの履歴が入っているように見えます。
実は変更履歴についての相談をいただいたときに changes を使うという方法もあるとお伝えしてしまったのですが、その後改めて確認してみると、少なくとも 8.0.0 や 9.0.0-beta ではクエリーを変更しても changes テーブルが更新されないので、現時点では changes を使ってクエリーの変更履歴を追うことはできないということがわかりました。
(クエリーの作成時、アーカイブ時は changes に履歴が残りますが、肝心のクエリー変更時の履歴が残らないようです)
もし、changes が利用できるようになるとクエリーの変更履歴はかなり追いやすくなると思います。
まとめ
残念ながら現時点で Redash においてクエリーの変更履歴を管理する方法において「たったひとつの冴えたやりかた」はなく、実現するにはなんらかの運用上の工夫が必要だと考えています。
クエリーの変更履歴を管理したい場合もそうでない場合も、スナップショットはとっておきましょう。何か問題が起こったときに、そのスナップショットが助けてくれるかもしれません。
勝手にまとめる 2020年の Redash 関連 Advent Calendar 記事
(この記事は私自身のためのメモのようなものです)
Google と Twitter を見直して、昨年末の Advent Calendar で、記事中に Redash という単語が出てきているものをリストにしてみました。
ここに書いていない記事があれば Twitter などで教えてもらえるとうれしいです。
Redash 関連記事一覧
以下はURL 順
BASE さん
Ubie さん
LAPRAS さん
CAMPFIRE さん
オープンロジ さん
service.openlogi.com qiita.com
dely さん
misoca さん
READYFOR さん
テックタッチ さん
techtouch.jp tech.techtouch.jp
面白法人カヤック さん
www.kayac.com techblog.kayac.com
LCL さん
www.lclco.com techblog.lclco.com
エムスリー さん
corporate.m3.com www.m3tech.blog
ランサーズ さん
Redash のモデルが持っているメソッドを Python コンソールから呼んでみたい
Redash のとあるモデルのメソッドを呼び出してみたとき、どんな結果が返ってくるか気になる時がありますよね。
そんなときは Python コンソールで確認してみましょう。
検証に使った Redash のバージョンは v8.0.0。Docker Based Developer Installation Guide の手順にしたがって環境構築しました。
やってみた
➜ redash git:(a16f551e2) ✗ docker-compose exec server bash redash@19df75427d3a:/app$ python Python 2.7.16 (default, Aug 14 2019, 13:44:33) [GCC 8.3.0] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> from redash.app import create_app >>> from redash.models import Query >>> app = create_app() >>> app.app_context().push() >>> [row for row in Query.all_queries(group_ids=[2], include_drafts=True)] [Query(id=1, name=u'New Query', query_hash=u'd7d1d45bcb946547b382bb0e7853c185', version=1, user_id=1, org_id=1, data_source_id=1, query_hash=u'd7d1d45bcb946547b382bb0e7853c185', last_modified_by_id=1, is_archived=False, is_draft=True, schedule=None, schedule_failures=0)]
便利ですね!これは調査が捗ります。
はまりどころ
postgres に接続できない。
v8.0.0 をチェックアウトして docker-compose run --rm server create_db したところ、以下のようなエラーがでていました。
sqlalchemy.exc.OperationalError: (psycopg2.OperationalError) could not translate host name "postgres" to address: Name or service not known (Background on this error at: http://sqlalche.me/e/e3q8)
postgres サービスのログをみると、今度は以下のようなログが出ていました。
postgres_1 | Error: Database is uninitialized and superuser password is not specified. postgres_1 | You must specify POSTGRES_PASSWORD to a non-empty value for the postgres_1 | superuser. For example, "-e POSTGRES_PASSWORD=password" on "docker run". postgres_1 | postgres_1 | You may also use "POSTGRES_HOST_AUTH_METHOD=trust" to allow all postgres_1 | connections without a password. This is *not* recommended. postgres_1 | postgres_1 | See PostgreSQL documentation about "trust": postgres_1 | https://www.postgresql.org/docs/current/auth-trust.html
どこかのタイミングで認証方法が変わったのでしょうか。とりあえず開発環境としては環境変数に POSTGRES_HOST_AUTH_METHOD=trust と書いておけば良いようです。Redash の master でもその方法で対応されていました。
モデルのメソッドを呼ぼうとするとエラーがでる
最初に検証しようとしたコードは以下のようなものでした。
from redash.models import Query [row for row in Query.all_queries(group_ids=[2], include_drafts=True)]
しかし、これを実行してもエラーが発生します。
RuntimeError: No application found. Either work inside a view function or push an application context. See http://flask-sqlalchemy.pocoo.org/contexts/.
このエラーについては、丁寧に参照すべきドキュメントの URL が記載されているので確認してみると、Flask アプリケーションを初期化し、app.app_context().push() することでエラーが解消できるようでした。
感想
がっつり調査をするときは PyCharm を使って Debug することが多いのですが、ちょっとした検証をするのに便利な方法が見つかってよかったですね。
Redash 上で桁数が多い数値を表示すると発生する誤差について調べた
久しぶりの記事もやはり Redash 関連でした。
結論を先に(個人の感想・意見です)
- Redash の UI 上で
9007199254740991を超える数値を扱いたい場合は、精度が下がることを許容するか文字列として扱う - これは JavaScript の仕様によるものなので、当面は Redash のバージョンアップだけで対応される可能性は低い
- Redash についての質問はぜひ Redash 日本語フォーラム で!
きっかけ
このツイートを目にしたことがきっかけでした。
やっぱりredashで18, 19桁くらいの大きめの数字を表示した際に下三桁くらいが本来の値と食い違うなぁ
— しょっさん@ʕ ◔ϖ◔ʔ (@syossan27) 2020年11月24日
いったん「redash じゃなくて Redash」については気にしないことにしましょう。
以前も似たようなツイートを見た覚えがあるのですが、ちょっと気になったので調べてみたくなりました。
再現してみる
環境について
データソースは SQLite 以外に MySQL 5.7 や PostgreSQL 9 でも確認し、同様の現象が発生することを確認していますが、この記事では手元の環境で検証したいので SQLite を使用して検証をした結果について書いていきます。
また、Redash についても 7.0.0, 8.0.0 で同様の現象が発生していることを確認していますが、こちらも手元の環境に合わせて 9.0.0-beta を使用しています。
再現手順
実行したクエリーは以下です。
select 12345678901234567890 foo;
クエリの実行結果を見ると、下3桁が違っていることに気づきます。
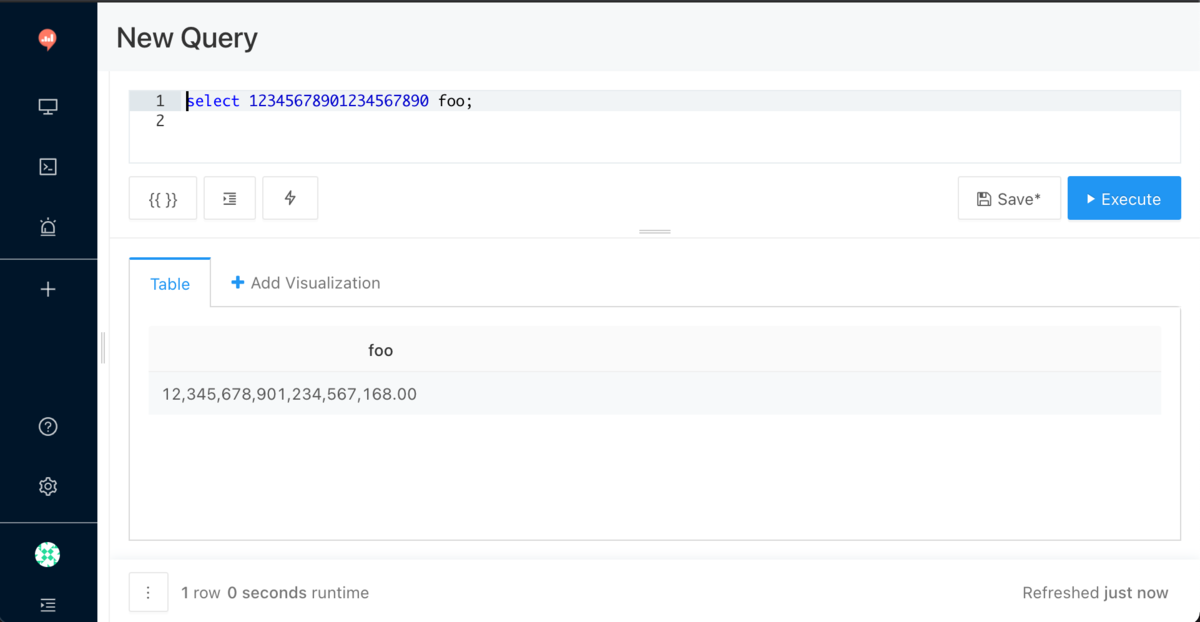
17桁にしてみても、まだ誤差がある。
select 12345678901234567 foo;

16桁にしてみると、どうやら問題なさそう。
select 1234567890123456 foo;

ツイートされていた現象は17桁以上の数値を扱おうとすると遭遇するようです。
原因を考える
どこで誤差が発生しているのかを考えて、ざっくり以下のようにわけてみました。
- Redash のフロントエンド(HTML / JavaScript)
- Redash のサーバーサイド/API(Python)
- Redash のワーカー(Python)
- データソース(接続先による)
ここまでの調査で以下の仮説があったので、フロント寄りをみていくことにします。
- 複数のデータソースで現象を確認しているので、データソースよりもフロント寄りで起きていそう
- 大きな値ではあるが、Python で扱えない桁数ではなさそう
- (17桁でも起きるので Python の int の最大値
2**63 - 1は関係なさそう)
- (17桁でも起きるので Python の int の最大値
調査してみる
調査については以下のクエリーを使っていきます。
select 12345678901234567 foo;
サーバーサイドをみる
Redash のサーバーサイドの処理はほとんどが REST(RESTish?) API になっているため、クエリーの結果も API が返します。まずはそのレスポンスをみてみました。
確認手順の詳細は割愛しますが、以下が API から取得できる JSON です。
{ "query_result": { "id": 18, "query_hash": "13f6db1bd3a5470f7d0641d1a7a380eb", "query": "select 12345678901234567 foo;\n", "data": { "columns": [ { "name": "foo", "friendly_name": "foo", "type": "integer" } ], "rows": [ { "foo": 12345678901234567 } ] }, "data_source_id": 1, "runtime": 0.00493335723876953, "retrieved_at": "2020-11-24T13:44:31.532Z" } }
API は 12345678901234567 という値を返してくれているようなので、API より手前側で何かが起きているというのは正しそうです。
フロントエンドをみる
ふと、12345678901234567 を JavaScript は数値として扱えるのかなと思ったので、開発者ツールのコンソールで試してみました。

入力に対し、結果として表示される値が変わっていますね。このあたりにヒントがありそうです。
もう少し調べてみる
MDN を参照してみたところ「Number の整数の範囲」という項目がありました。おそらくこれが原因を表しているのだと思います。
JavaScript で扱えるの最大値は 9007199254740991 ということと、JSON で 9007199254740991 を超える値をデシリアライズすると信頼できない値になることについて触れられているので、試してみましょう。
select 9007199254740991 foo , 9007199254740992 bar , 9007199254740999 baz;
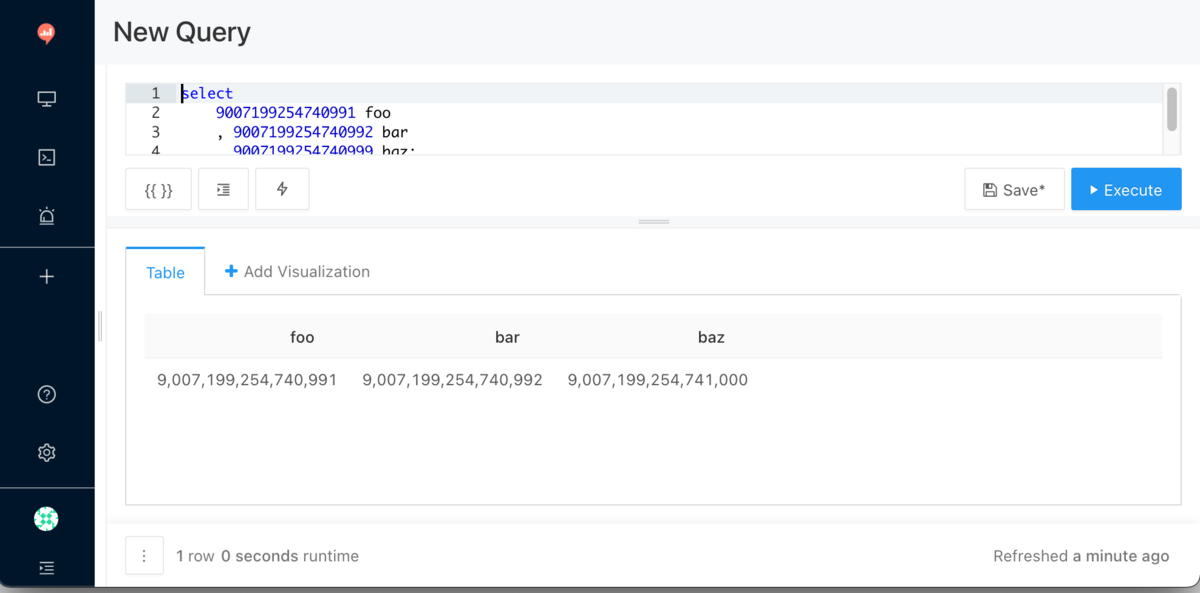
9007199254740992 にしても結果は変わらないようにみえますが、9007199254740999 は結果が 9007199254741000 となっていて 1 多いので、信頼できないといえそうです。
JavaScript の Number の最大値から離れれば離れるほど、かつ、Python の int の最大値を超えない範囲ではこの「信頼できない数値」問題が発生すると考えます。
対策
冒頭に結論を書きましたが、数値としてそのまま扱うことは今のところ難しく、MDN にも以下のような記載があります。
可能な回避策として、代わりに String を使用してください。
大きい数値は BigInt 型を用いて表すことができます。
文字列として扱うというのは「あるある」だと思いますが、Visualization で使う際にはどこかで数値にキャストされているようで、誤差のある状態の数値となってしまいます。
ある程度は誤差を許容して使うか、金額であれば千円や百万円単位にするなど、桁数をクエリ側で調整するなどの工夫も考えられます。

BigInt については、どうやら期待を満たしてくれそうではありますが、これは Redash 単体だけでは解決しない可能性が高く、すぐに解決するようなことではないと思いました。

まとめ
ふと目にしたツイートきっかけで、意外な事実を知ることができました。
Redash は 17桁を超えるような数値を扱うような環境でも使われている(?)ということに、Redash ファンとして嬉しさも感じつつ、調査を進められた気がします。
私は趣味で Redash エゴサをしていますが、なにか質問などあれば、ぜひフォーラムへ投稿をおねがいします。
Redash のフォーラムには日本語チャンネル(英語以外の言語チャンネルは日本語だけ!)があるので、日本語で質問できますし、私も知っている限りの範囲になりますが、フォーラムで質問に回答しています。
Happy Querying!
いまさら Redash の マルチバイト検索対応について調べてみた

設定画面にある Feature Flags > Enable multi-byte。
日本のユーザーならオンにしていることが多いと思いますが、この設定をオンにすると内部的には何が起きるのか。
v9.0.0-beta ブランチで確認した結果、答えは「PostgreSQL の全文検索の仕組みを使わず、キーワードがクエリ名または説明文に含まれるかを ILIKE で部分一致検索する」でした。
日本語で全文検索と言えば PGroonga が思いついたのでドキュメントを眺めてみると、PostgreSQL の全文検索は英数字のみサポートしていると書いてありました。
Redash が内部的に利用している SQLAlchemy-Searchable が CJK をサポートしていないのかと思っていたのですが、どうやら PostgreSQL の全文検索の制約のようです。
PGroonga は Docker イメージも公開されているので、Redash に組み込めるか検証したくなってきました。