メモ: Docker コンテナー内の puppeteer からホスト上の Chrome を操作する
M1 Mac で Puppeteer を動かすのは大変というかできないみたいな話を聞いた気がする。
今のところ M1 Mac もってないので実際使えるかわからないけど、何となくこんな感じて回避できたりするかと思い、やってみたらできたのでメモ。
手順
まずはファイルをいろいろ準備する。
Dockerfile
FROM node:16 WORKDIR /app COPY main.js proxy.js /app/ RUN npm i http-proxy puppeteer-core --save CMD node proxy.js
main.js
const Puppeteer = require('puppeteer-core'); async function main() { const browser = await Puppeteer.connect({ browserURL: 'http://127.0.0.1:9222', }); const page = await browser.newPage(); await page.goto('https://example.com/'); } main();
proxy.js
これは main.js から host.docker.internal:9222 には直接つなげられない感じだったので雰囲気でやっている。
const httpProxy = require('http-proxy'); httpProxy .createProxyServer({ target: 'http://host.docker.internal:9222', ws: true, }) .listen(9222);
イメージをビルド
docker build -t puppeteer-with-chrome-on-host-os .
Mac 上で Chrome を起動する
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome \ --remote-debugging-port=9222 \ --no-first-run \ --no-default-browser-check \ --user-data-dir=$(mktemp -d -t 'chrome-remote_data_dir')
コンテナーを起動
docker run -it --rm puppeteer-with-chrome-on-host-os
何とかしてコンテナーに入る
docker exec -it [コンテナーID] bash
コンテナーで puppeteer を使ったスクリプトを実行
node main.js
うまくいけば Mac 上で起動した Chrome が以下のようになる。

メモ: Ubuntu 20.04 に Embulk v0.9 を導入する
たまに Embulk の環境作ろうとすると JDK 11 をインストールしてしまったりする自分向けのメモ。
$ sudo apt-get update $ sudo apt-get install -y openjdk-8-jdk # 以下は公式サイトの手順そのまま https://www.embulk.org/ $ curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar" $ chmod +x ~/.embulk/bin/embulk $ echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc $ source ~/.bashrc # Embulk を使いたい時は大抵 BigQuery に書き込みたいのでプラグインも入れておく $ embulk gem install embulk-output-bigquery
これでもう忘れても大丈夫。
Redash でひとつのクエリを admin グループ所属ではない複数のユーザーで編集するための設定
TL;DR
実験的な機能として、環境変数 REDASH_FEATURE_SHOW_PERMISSIONS_CONTROL を true にすると、クエリー作成者のクエリー編集画面のメニューに Manage Permissions が表示されるようになり、作成者以外にも編集権限を付与できるので、複数人でクエリーを編集できる。
検証環境の前提
- Redash v8.0.0(v4.0.1でも確認済み)
- ユーザー
- admin
- user1
- user2
- グループ
- admin
- admin ユーザーのみが所属
- default
- すべてのユーザーが所属
- admin
- データソース
環境変数の設定
Docker Compose で Redash の環境を構築している場合、environment に以下の設定を追加する
REDASH_FEATURE_SHOW_PERMISSIONS_CONTROL: "true"
Redash v6.0.0 以降では、admin 権限を持つユーザーであれば、Settings の画面から設定を切り替えることもできる。

使い方
user1 での作業
新規クエリーを作成する。作成したクエリーの ID は 1 とする。

クエリーエディター右上のメニューから Manage Permissions を選択する。
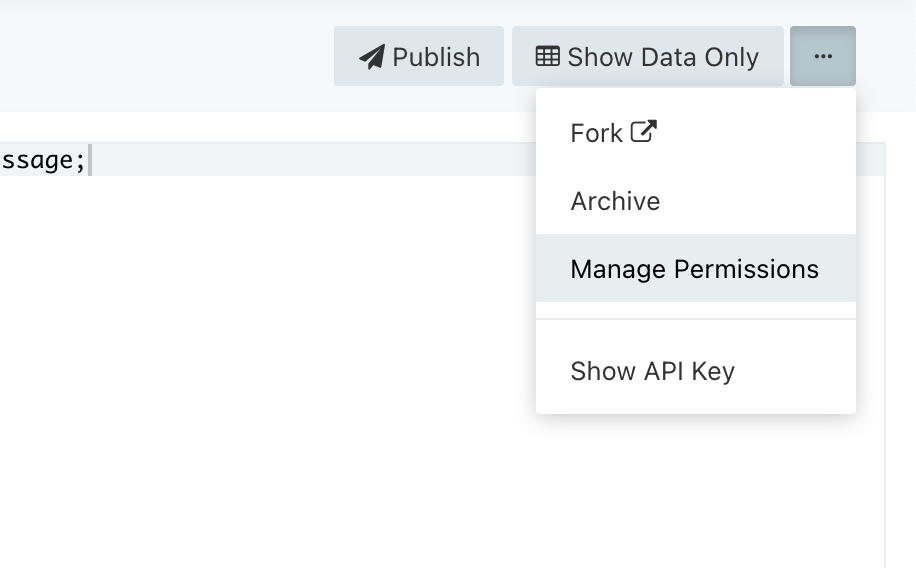
クエリーの権限設定の画面が表示されるので、user2 に権限を追加する。

user2 での作業
クエリー一覧などから、user2 でクエリー ID 1のクエリーにアクセスする。v4.0.1 では user2 のクエリー一覧に表示されないが、URL を直接指定してアクセスすることはできる。
クエリーが表示できたら、Edit Source をクリックすると、環境変数設定前は作成者か admin グループ所属ユーザーでなければ表示されない Save ボタンが表示されるので、user2 でクエリーを変更し保存・実行してみる。
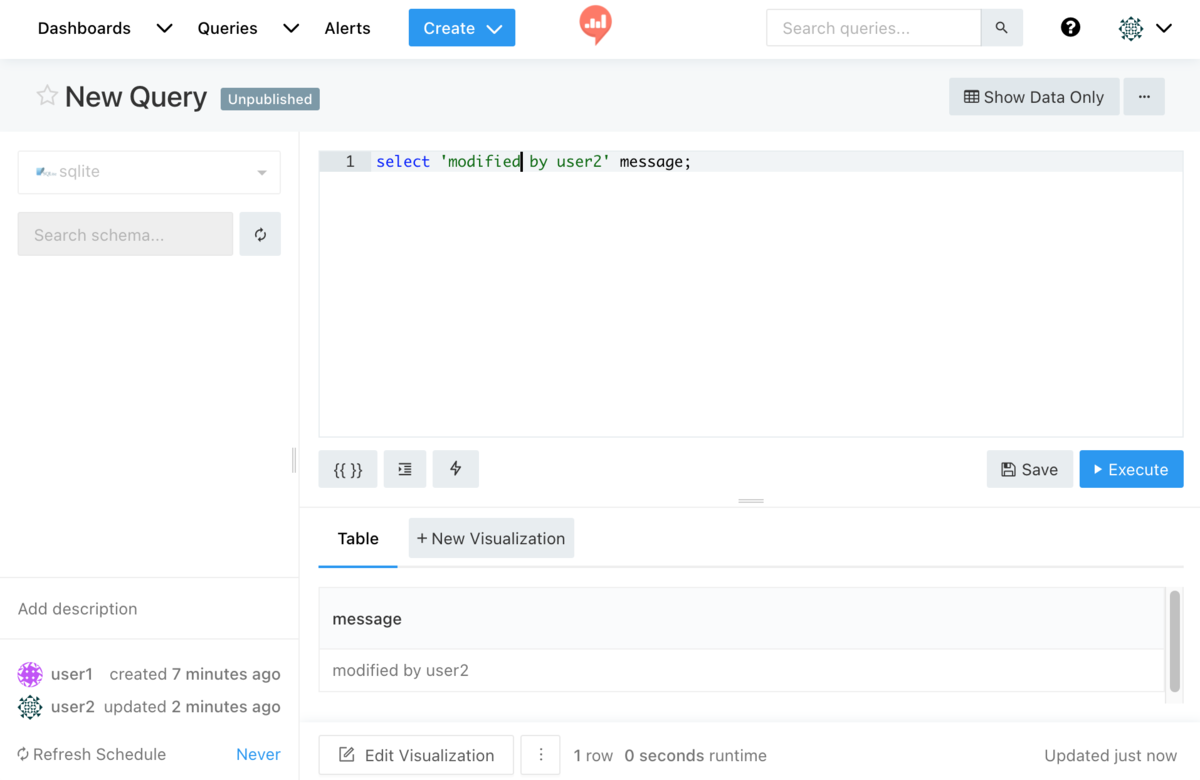
user2 はクエリーの所有者ではないため、クエリーエディター右上のメニューには Manage Permissions が表示されない。
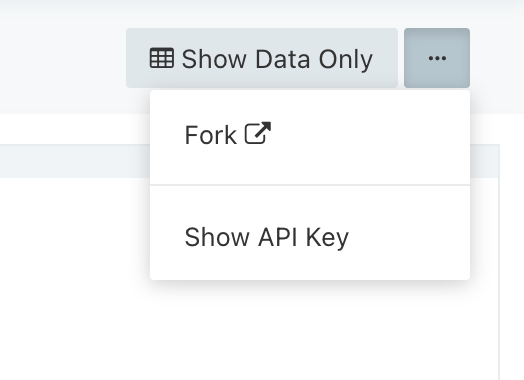
仕組み
access_permissions というテーブルに以下のようなレコードが挿入される。

詳細な実装までは追っていないが、Redash がクエリーの編集権限を確認する際、(管理者または所有者)またはアクセス権を持っている(=access_permissions テーブルにレコードがある)ことを条件としているため、管理者・所有者以外のユーザーでも編集操作を許可されているようだ。
注意点
私が調べた限り、権限割当後に REDASH_FEATURE_SHOW_PERMISSIONS_CONTROL を false にしても、access_permissions にはレコードが残り続けるため、権限を剥奪は REDASH_FEATURE_SHOW_PERMISSIONS_CONTROL を true にした状態で、所有者が明示的に行う必要がある。
まとめ
実験的な機能であるため、本番導入時には事前の検証や、Redash の DB バックアップ取得をおすすめするが、管理者権限がなくても複数人でクエリーを編集できるメリットは大きいので、興味があれば試してみてほしい。
Happy Redash-ing!
今すぐできる Redash の健康診断
Redash のトラブルシューティングをしていて、手癖のようなものがあることに気づいたので紹介しておきます。
前提
- 利用している Redash は v8.0.0 の Self-hosted を想定
- Redash のデータベースにアクセスできること
- 文中では
psqlを使用していますが、Redash の postgres に接続できればクライアントは特に限定しません
- 文中では
その定期実行は本当に必要ですか?
無邪気に設定された定期実行がキューを詰まらせていることがあるかもしれません。
特に「毎分」実行になっているものがあったら要注意です。以下の SQL で定期実行の間隔が短いものを確認してみましょう。
もし、短い間隔で実行されているクエリーが見つかったら、そのクエリーを確認し、現在でも利用されているか?本当に定期実行が必要か?定期実行の間隔は適切か?を見直してみましょう。
select id , (schedule::json->>'interval')::INT as interval , created_at , updated_at from queries where is_archived=false order by interval limit 100 ;
実行例
postgres=# select postgres-# id postgres-# , (schedule::json->>'interval')::INT as interval postgres-# , created_at postgres-# , updated_at postgres-# from postgres-# queries postgres-# where postgres-# is_archived=false postgres-# order by postgres-# interval postgres-# limit 100 postgres-# ; id | interval | created_at | updated_at ----+----------+-------------------------------+------------------------------- 4 | 60 | 2021-03-02 13:33:40.378489+00 | 2021-03-02 13:33:59.178892+00 2 | 600 | 2021-02-11 04:15:33.374336+00 | 2021-03-02 13:34:08.125934+00 (2 rows)
重いクエリーを見落としていませんか?
Redash の活用が進むにつれて、作成当時はすぐに結果が返っていたクエリーも、時間が経ってデータ量が増えていたり、データの構造が変わって想定を超えるデータ量を扱うことになってしまっているという状況もありえます。
以下の SQL で、実行に時間がかかっているものを確認してみましょう。
実行に時間がかかっているクエリーが見つかった場合、SQL のチューニング、データのパーティショニング、データソース側のスケールアップなど、データソースや対象のデータの特性によっても扱いは変わりますが、実行時間を短くできるか検討してみましょう。
select qr.id , qr.query_hash , qr.runtime , qr.retrieved_at , q.id query_id from query_results qr left join queries q on qr.query_hash = q.query_hash or qr.id order by qr.runtime desc limit 100 ;
実行例
postgres=# select
qr.id
, qr.query_hash
, qr.runtime
, qr.retrieved_at
, q.id query_id
from
query_results qr
left join
queries q on qr.query_hash = q.query_hash
order by
qr.runtime desc
limit 100
;
id | query_hash | runtime | retrieved_at | query_id
----+----------------------------------+----------------------+-------------------------------+----------
39 | 5a6ac618d80fde285f76b0fda8138395 | 0.00146913528442383 | 2021-03-02 14:02:46.552977+00 |
35 | e1d51032e9f9e91e5bf3c94e87491fc6 | 0.00141096115112305 | 2021-03-02 13:59:57.11131+00 |
33 | 9c021c8d73b6c64005b2d748b40c758b | 0.00129294395446777 | 2021-03-02 13:59:44.440632+00 |
...省略...
48 | 7830e05b1c1fe5cfde05865bb3837e86 | 0.000459909439086914 | 2021-03-02 14:06:20.15143+00 | 4
36 | 7830e05b1c1fe5cfde05865bb3837e86 | 0.00043177604675293 | 2021-03-02 14:00:20.126168+00 | 4
18 | 7830e05b1c1fe5cfde05865bb3837e86 | 0.000409841537475586 | 2021-03-02 13:40:19.92023+00 | 4
(38 rows)
上記の実行例では重いクエリーは見受けられませんが、runtime の値が大きなクエリー結果は注意してみましょう。どの程度を「大きい」と捉えるかは、利用しているデータソースや扱うデータ量などによっても異なるので、適宜判断してください。
クエリーパラメータを使用していない場合は query_hash で該当のクエリーの ID を突き止めることができますが、それができない場合はクエリー結果の id を使って実行されたクエリーを特定し、実行されたクエリーの部分文字列を使って該当のクエリーを探すことになります。
postgres=# select query from query_results where id = 39;
query
-----------------------
select 1 hello;
(1 row)
postgres=# select id from queries where query like '%select 1 hello;%';
id
----
6
(1 row)
キューが詰まったときの対応についておすすめの記事
Redash のクエリー結果が自動的にクリーンアップされない場合があるので調査しました
きっかけはこちらの投稿です。フォーラムへの投稿ありがとうございます!
遅くなってしまいましたが、私の理解も改めるきっかけになったので調査結果を残しておきます。
現象
Redash のクエリーが自動的にクリーンアップされる設定をしているにも関わらず、ディスク容量が開放されないとのことでした。
当初の私は、一度にクリーンアップする結果の数を指定する QUERY_RESULTS_CLEANUP_COUNT と、クリーンアップ対象の結果のオフセット(日単位)を指定する QUERY_RESULTS_CLEANUP_MAX_AGE の設定によっては、クリーンアップが遅れたり、自動実行されているクエリーが大量に存在する場合は、クリーンアップが追いつかずに結果が溜まってしまうのかと思っていましたが、どうやら違う原因もあるようでした。
調査内容
調査には安定版の v8.0.0 を使用しました。
クリーンアップに関わるコードを追っていく
クエリー結果のクリーンアップは Celery のタスクで実行されており、以下にタスクが定義されています。
https://github.com/getredash/redash/blob/v8.0.0/redash/tasks/queries.py#L235
クリーンアップ対象のクエリー結果は、以下のコードで取得しています。
unused_query_results = models.QueryResult.unused(settings.QUERY_RESULTS_CLEANUP_MAX_AGE).limit(settings.QUERY_RESULTS_CLEANUP_COUNT)
ここで呼び出されている models.QueryResult クラスの unused メソッドは以下のように定義されています。
Redash のコードやメタデータの定義に詳しい方は、このコードを見た時点で気になることが見つかるかもしれません。
https://github.com/getredash/redash/blob/v8.0.0/redash/models/__init__.py#L266
unused メソッドの中で実行されている SQL
unused メソッドで実行されている SQL を見てみると、以下のようになっていました。
SELECT query_results.id AS query_results_id FROM query_results LEFT OUTER JOIN queries ON query_results.id = queries.latest_query_data_id WHERE queries.id IS NULL AND query_results.retrieved_at < %(retrieved_at_1)s LIMIT %(param_1)s
参考として、Redash のメタデータの queries と query_results のテーブル定義を紹介しておきます。
Table "public.queries"
Column | Type | Modifiers
----------------------+--------------------------+------------------------------------------------------
updated_at | timestamp with time zone | not null
created_at | timestamp with time zone | not null
id | integer | not null default nextval('queries_id_seq'::regclass)
version | integer | not null
org_id | integer | not null
data_source_id | integer |
latest_query_data_id | integer |
name | character varying(255) | not null
description | character varying(4096) |
query | text | not null
query_hash | character varying(32) | not null
api_key | character varying(40) | not null
user_id | integer | not null
last_modified_by_id | integer |
is_archived | boolean | not null
is_draft | boolean | not null
schedule | text |
schedule_failures | integer | not null
options | text | not null
search_vector | tsvector |
tags | character varying[] |
Table "public.query_results"
Column | Type | Modifiers
----------------+--------------------------+------------------------------------------------------------
id | integer | not null default nextval('query_results_id_seq'::regclass)
org_id | integer | not null
data_source_id | integer | not null
query_hash | character varying(32) | not null
query | text | not null
data | text | not null
runtime | double precision | not null
retrieved_at | timestamp with time zone | not null
SQL とテーブル定義を読み解くと。queries テーブルの last_modified_by_id で参照されていない、かつ、retrieved_at が指定の日時(現在時刻 - 環境変数で指定したオフセット)より古い query_results の id を抽出しているということがわかります。
ここだけ見ると、クリーンアップ対象となるクエリーを抽出できていそうにみえますが、この SQL ではクリーンアップ対象として取得できないクエリー結果が残ってしまいます。
どんなクエリー結果が残ってしまうのか
前述の SQL でクリーンアップ対象として取得できないクエリー結果は「アーカイブされたクエリーのクエリー結果」となります。
Redash のクエリーはアーカイブという状態をもっており、queries テーブルの is_archived が true のものはアーカイブ状態として扱われています。
ここで先程のクエリーを見直してみると、latest_query_data_id の関連やクエリー結果の取得日時は条件として指定されていますが、クエリーがアーカイブされているものは考慮されていないため、アーカイブされたクエリーが最後に取得した結果 はクリーンアップされず延々と残ってしまいます。
この挙動が意図的なものかどうかはわかりませんが、アーカイブされたクエリー結果もクリーンアップするためには、クエリーのアーカイブ処理やクリーンアップ処理周りの修正が必要になると思われます。
残ってしまったクエリー結果をどうするか
アーカイブしたクエリー結果が残ってしまった場合、設定などで簡単に回避できるものではないため、運用に影響がない場合はそのままにするのが良いと考えています。